[JAVA] 로그분석기
멘토링 두 번째 코딩 과제였던 로그분석기입니다.
이번 과제에서도 PR을 진행했습니다.
main branch와 제가 commit 하는 develop branch로 나누어서 develop branch에만 PR을 진행했습니다.
처음에는 하루 만에 코드를 짜느라 클래스 나누는 거 하나도 안 하고 그냥.. 메인에 다 때리는 식으로 작성했지만.. 멘토님들의 소리 없는 아우성을 듣고 일주일 동안 열심히 고쳤습니다. 클래스도 나누고 테스트 코드 작성 연습도 해봤습니다.
무엇보다 처음으로 maven의 편리성을 실감했습니다. apache commons 라이브러리도 사용해봤습니다.
전체 코드
https://github.com/CDG-2022/gayeon-log-Analysis
GitHub - CDG-2022/gayeon-log-Analysis: 2. log-Analysis
2. log-Analysis. Contribute to CDG-2022/gayeon-log-Analysis development by creating an account on GitHub.
github.com
코드 설명
main.java
package com.cdg;
import java.io.*;
public class main
{
public static void main( String[] args ) throws IOException {
AnalysisManager analysisManager = new AnalysisManager();
analysisManager.analysisStart();
}
}main 문입니다.
3줄 이하로 만들려고 노력했습니다.. 옛날 c++ 수업 때 교수님이 main 문 3줄 넘으면 어쩌구~ 하셨던 내용 때문에 계속 그렇게 작성합니다. 그래서 그런지 딱히 설명할 내용 없습니다. 로그 분석 매니저를 만들고, 매니저가 로그 분석을 시작한다. 로 이해해 주시면 됩니다.
AnalysisManager.java
package com.cdg;
import java.io.IOException;
public class AnalysisManager {
private LogMap logMap = new LogMap();
private LogParser logParser = new LogParser();
private LogFileWriter logFileWriter = new LogFileWriter();
public void analysisStart() throws IOException {
logParser.logParse(logMap);
logFileWriter.logFileWriter(logMap);
}
}AnalysisManager 클래스가 들고 있어야 할 게 뭘까.. 로그 분석을 위해 들고 있어야 할 것.. 을 생각하다 보니 이렇게 됐습니다.
1. 파싱 한 로그를 예쁘게 들고 있을 메모리 (LogMap)
2. 로그를 파싱 할 가위 (LogParser)
3. 로그 파일(output)을 쓸 수 있는 도구 (LogFileWritter)
매니저는 이렇게 들고 있습니다. analysisStart 함수는 로그 파싱하고, 로그 파일을 씁니다. 정말 간단합니다.
LogMap 클래스는 설명하지 않겠습니다. 그냥 Map 집합소라고 생각하시면 됩니다.
LogParser.java
package com.cdg;
import org.apache.commons.lang3.StringUtils;
import java.io.IOException;
public class LogParser {
private LogFileReader logFileReader = new LogFileReader();
public void logParse(LogMap logMap) throws IOException {
logFileReader.logFileOpen();
while (true) {
String[] splitLog = StringUtils.substringsBetween(logFileReader.logFileRead(), "[", "]");
if (splitLog == null) break;
logMap.getStateCodeMap().put(splitLog[0], logMap.getStateCodeMap().getOrDefault(splitLog[0], 0) + 1);
logMap.getApiServiceMap().put(StringUtils.substringBetween(splitLog[1], "search/", "?"), logMap.getApiServiceMap().getOrDefault(StringUtils.substringBetween(splitLog[1], "search/", "?"), 0) + 1);
logMap.getApiKeyMap().put(StringUtils.substringBetween(splitLog[1], "=", "&"), logMap.getApiKeyMap().getOrDefault(StringUtils.substringBetween(splitLog[1], "=", "&"), 0) + 1);
logMap.getWebBrowserMap().put(splitLog[2], logMap.getWebBrowserMap().getOrDefault(splitLog[2], 0) + 1);
logMap.getPeakTimeMap().put(splitLog[3].substring(0, splitLog[3].length()-3), logMap.getPeakTimeMap().getOrDefault(splitLog[3].substring(0, splitLog[3].length()-3), 0) + 1);
}
logFileReader.logFileClose();
}
}드디어 아파치 커먼랭 라이브러리를 사용합니다.
로그 파싱을 하려면 일단 들어오는 로그 파일을 읽어야겠죠. LogFileReader 클래스를 갖고 있습니다.
읽고 난 후에는 그 파일 읽기가 끝날 때까지 계속 파싱 해주는 작업입니다. 처음으로 getOrDefault 함수를 써봤는데 편하고 예쁘더라고요. 프로그래머스 문제 풀 때도 잘 쓰고 있습니다. 정규식을 이용해 파싱 할 수도 있었겠지만 전 아직 정규식을 잘 활용하지 못합니다. 그래서 그냥 들어오는 로그 형식에 맞춰 잘라줬습니다. (그럼 코드에서 짠 형식에 벗어난 코드는 ? 당연히 다른 데이터들과 다르게 이상하게~ 됩니다)
LogFileWritter.java
package com.cdg;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
public class LogFileWriter {
private MapSorter mapSorter = new MapSorter();
private static final String OUTPUT_FILE_NAME = "output.log"; // 쓰려는 file name
public void logFileWriter(LogMap logMap) throws IOException {
File file = new File(OUTPUT_FILE_NAME);
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file);
PrintWriter printWriter = new PrintWriter(fileWriter);
printWriter.write("최다호출 APIKEY\n\n");
if (mapSorter.getMaxValues(logMap.getApiKeyMap()).size() != 0) {
for (int i = 0; i < mapSorter.getMaxValues(logMap.getApiKeyMap()).size(); i++) {
printWriter.write((String) mapSorter.getMaxValues(logMap.getApiKeyMap()).get(i) + "\n\n");
}
}
printWriter.println();
printWriter.write("상태코드 별 횟수\n\n");
if (mapSorter.sortOrderByKeyAsc(logMap.getStateCodeMap()).size() != 0) {
for (int i = 0; i < mapSorter.sortOrderByKeyAsc(logMap.getStateCodeMap()).size(); i++) {
printWriter.write( (String) mapSorter.sortOrderByKeyAsc(logMap.getStateCodeMap()).get(i) + "\n");
}
}
printWriter.println(); printWriter.println();
printWriter.write("상위 3개의 API ServiceID와 각각의 요청 수\n\n");
if (mapSorter.sortOrderByValueDesc(logMap.getApiServiceMap(), 3, false).size() != 0 ) {
for (int i = 0; i < mapSorter.sortOrderByValueDesc(logMap.getApiServiceMap(), 3, false).size(); i++) {
printWriter.write((String) mapSorter.sortOrderByValueDesc(logMap.getApiServiceMap(), 3, false).get(i) + "\n");
}
}
printWriter.println(); printWriter.println();
printWriter.write("피크 시간대\n\n");
if (mapSorter.getMaxValues(logMap.getPeakTimeMap()).size() != 0) {
for (int i = 0; i < mapSorter.getMaxValues(logMap.getPeakTimeMap()).size(); i++) {
printWriter.write((String) mapSorter.getMaxValues(logMap.getPeakTimeMap()).get(i) + "\n\n");
}
}
printWriter.println();
printWriter.write("웹 브라우저 별 사용비율\n\n");
if (mapSorter.sortOrderByValueDesc(logMap.getWebBrowserMap(), 5, true).size() != 0) {
for (int i = 0; i < mapSorter.sortOrderByValueDesc(logMap.getWebBrowserMap(), 5, true).size(); i++) {
printWriter.write((String) mapSorter.sortOrderByValueDesc(logMap.getWebBrowserMap(), 5, true).get(i) + "\n");
}
}
printWriter.close();
}
}로그 파일을 작성하기 위해 들고 있어야 할 것... 이 있나? 싶지만 요구하는 형식으로 작성하기 위해서는 MapSorter가 필요합니다.
내림차순 혹은 오름차순으로 데이터를 정렬해야 합니다.
이 클래스에서는 MapSorter을 이용해 원하는 값을 가져오고 그것을 파일에 쓰는 일이 다...입니다.
MapSorter.java
package com.cdg;
import java.io.PrintWriter;
import java.util.*;
public class MapSorter {
public List getMaxValues(Map<String, Integer> map) { // 가장 큰 value 값의 key 반환
List<String> result = new ArrayList<String>();
int max = Collections.max(map.values());
for (Map.Entry<String, Integer> entry : map.entrySet()) {
if (entry.getValue() == max) {
result.add(entry.getKey());
}
}
return result;
}
public List sortOrderByKeyAsc(Map<String, Integer> map) {
List<String> keySet = new ArrayList<>(map.keySet());
Collections.sort(keySet);
List<String> result = new ArrayList<String>();
for (String key : keySet) {
result.add(key + " : " + map.get(key));
}
return result;
}
public List sortOrderByValueDesc(Map<String, Integer> map, int rank, boolean percent) {
List<String> keySet = new ArrayList<>(map.keySet());
keySet.sort((o1, o2) -> map.get(o2).compareTo(map.get(o1)));
List<String> result = new ArrayList<String>();
for (int i = 0; i < rank; i++) { // 상위 몇 개
if (percent) { // 비율로 표시
int total = map.values().stream().mapToInt(Integer::intValue).sum();
result.add(keySet.get(i) + " : " + String.format("%.1f", ((double)map.get(keySet.get(i)) / (double)total * 100)) + "%");
} else {
result.add(keySet.get(i) + " : " + map.get(keySet.get(i)));
}
}
return result;
}
// not use
public void sortKeyWriteFile(Map<String, Integer> map, PrintWriter printWriter) { // key 값 기준 정렬
List<String> keySet = new ArrayList<>(map.keySet());
Collections.sort(keySet);
for (String key : keySet) {
printWriter.write(key + " : " + map.get(key) + "\n");
}
printWriter.write("\n\n");
}
public void sortValueWriteFile(Map<String, Integer> map, int rank, boolean percent, PrintWriter printWriter) { // value 기준 정렬
List<String> keySet = new ArrayList<>(map.keySet());
keySet.sort((o1, o2) -> map.get(o2).compareTo(map.get(o1)));
for (int i = 0; i < rank; i++) {
if (percent) { // 비율로 표시
int total = map.values().stream().mapToInt(Integer::intValue).sum();
printWriter.write(keySet.get(i) + " : " + String.format("%.1f", ((double)map.get(keySet.get(i)) / (double)total * 100)) + "%\n");
} else {
printWriter.write(keySet.get(i) + " : " + map.get(keySet.get(i)) + "\n");
}
}
printWriter.write("\n\n");
}
}정말... 정말.. 오래 걸렸습니다. 이 클래스는..
코드가 길지만 쓰는 함수는 위에 3개입니다. not use 주석 아래는 쓰지 않는 함수입니다. (그럼 왜 안 지우냐? 뒤에 이유 나옴)
이걸 처음 작성할 당시에 Java는 정말 편한 언어라는 것을 느꼈습니다. 지금 다시 보니 sort 투성이지만 저 당시에는 대단하다고 생각했습니다. (극한의 c충 + 임베복전 시기) 어떻게 하면 메모리를 1bit라도 더 아낄 수 있을까에 집착하던 때라 중복되는 부분이 있습니다.
이제 코드에 대한 설명은 끝났습니다. (적고 보니 딱히 설명이 없네요?...)
코드 리뷰 PR
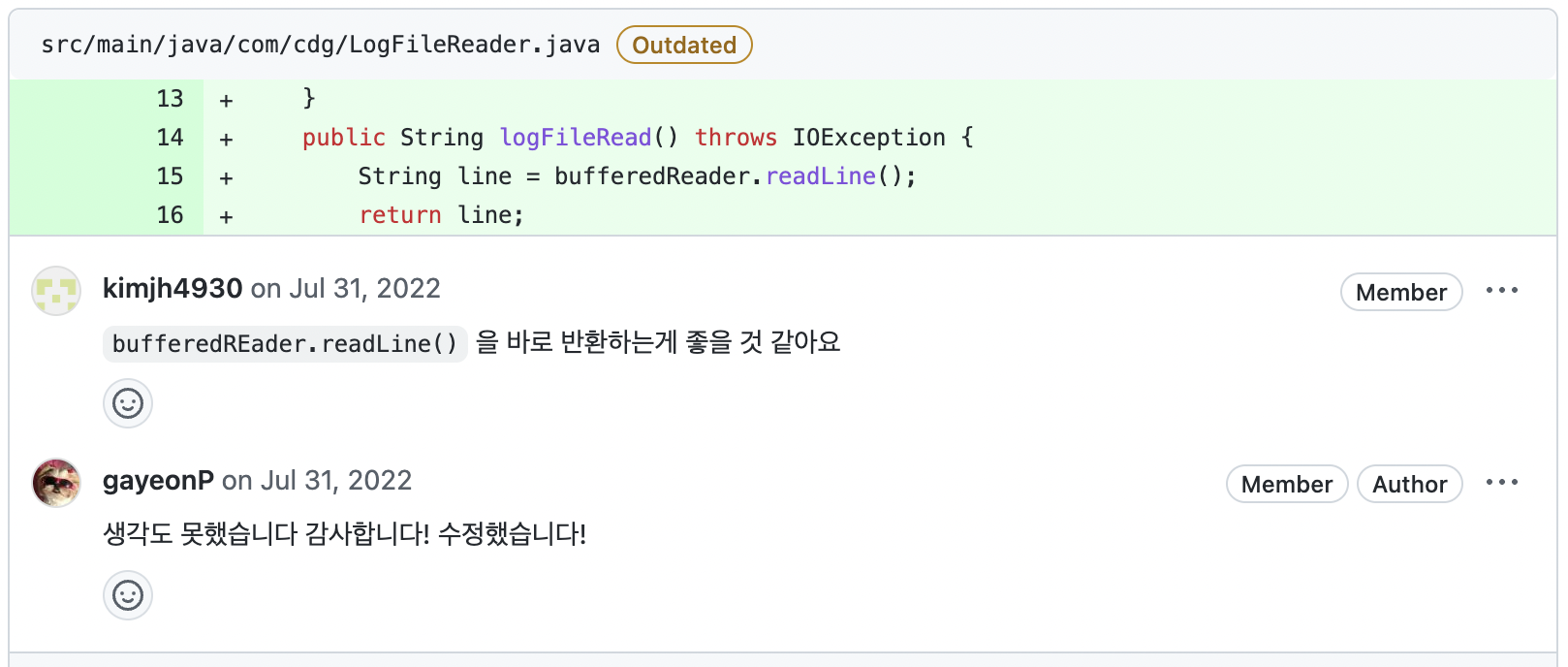
머 쓸 말이 없네요... ? 감사합니다.

이 부분은 온라인 코드 리뷰 때, 각 회사마다 각 팀마다 코드 규칙이 다른 것이니 그 팀 코드 규칙을 따르면 된다고 하셨습니다.

output file, input file 정말 모두 수정했습니다.

무릎 탁... Java가 부족하다는 것을 여실히 보여준 부분입니다. 그래서 저 나름대로 HashMap이 순서를 보장하지 않는다는 것을 테스트 코드를 만들어서 확인했습니다. 하지만 HashMap put 함수 원형을 보니 단순 연결 리스트로 구현된 거 같은데 next를 갖고 있다면 순서를 보장하지 않는 것이 이상하지 않나...? 라는 생각으로 질문했습니다.


이 답은 온라인 코드 리뷰 때 주셨는데요. 레드블랙트리로 구현된 거여서 그렇다고 하셨습니다. (아...!!!) Red/Black Tree 모르시는 분들은 이 사이트를 참고해서 공부하시면 좋습니다. 알고리즘 공부할 때 도움 많이 됐습니다.
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
Red/Black Tree Visualization
www.cs.usfca.edu
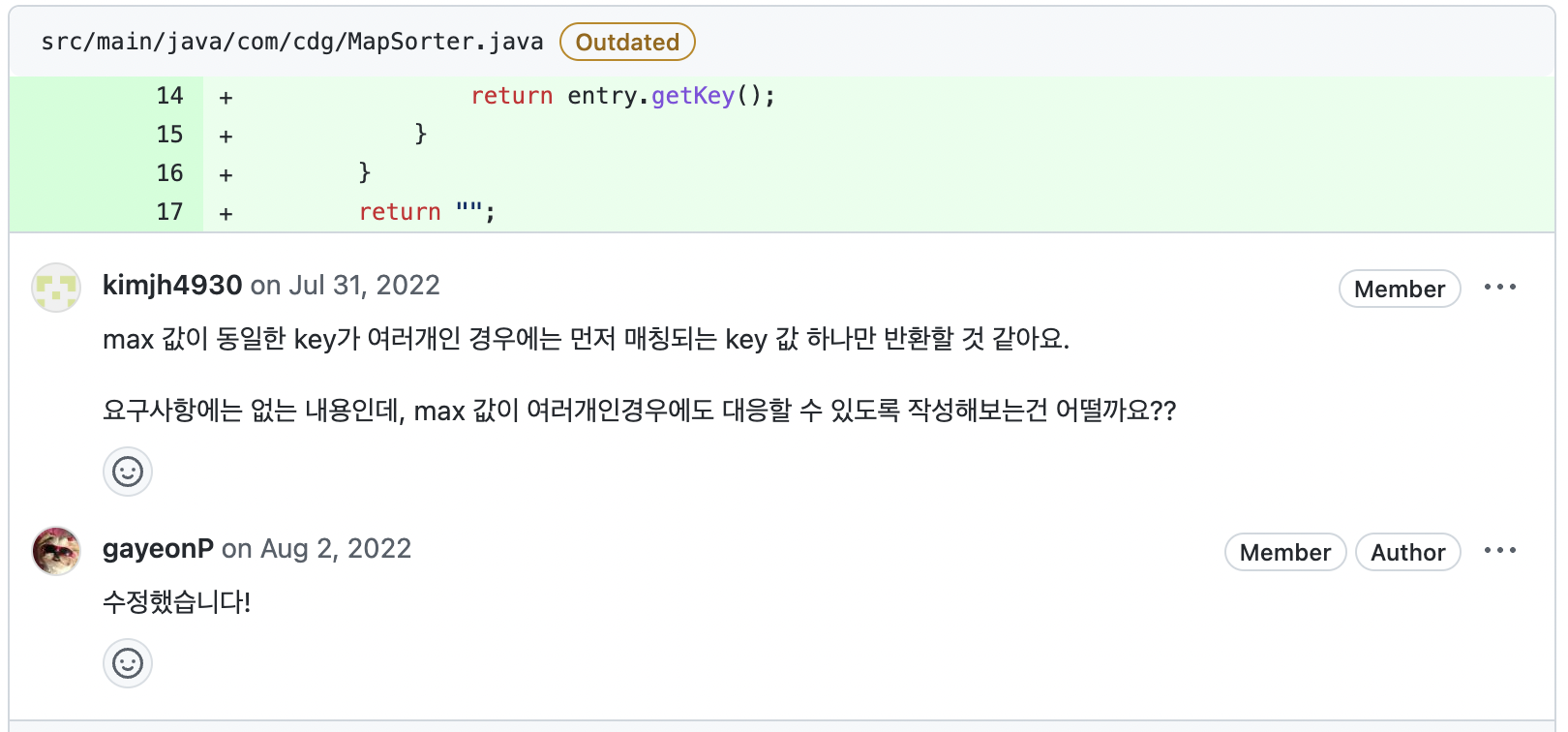
코드 실력 향상을 위해 좋은 피드백을 주신 선배님.. max값이 여러 개인 경우에도 대응할 수 있도록 하기 위해 파일 쓰기 부분에 for문을 추가했습니다. 작성하고 보니... 더 좋네...?

아까 MapSorter 클래스에서 안 쓰는 부분을 왜 안 지웠는지 밑에 이유가 나온다고 했는데 그 이유입니다.
원래는 PrintWriter 객체까지 파라미터로 받아 바로 쓰는 함수였는데 멘토님 의견을 듣고 보니 Sorter인데 왜 그랬지...? (왜긴.. 편하게 짜려고 그랬지..) 처음엔 어떻게 수정해야 하나 막막했는데, 해봐야죠 머.. 역시 작성하고 보니 멘토님 의견대로 수정한 게 훨씬 좋네요.
비교를 위해 지우지 않고 남겨두었습니다.
전체 PR이 궁금하시면 상단 깃허브 주소에 closed 된 PR 보시면 됩니다.
재밌었습니다. 주사위게임보다 훨씬 구현하는 데는 어려웠습니다.
처음에 클래스를 나누지 않고 구현해서 main에 전부 때렸다고 했는데 클래스를 어떻게 나눌지 고민하는 시간이 길어져서 그랬습니다.
고민하는 시간이 길어지는 거랑 클래스 안 나누는 것이 무슨 상관이냐면... 시간은 촉박한데... 고민.. 고민하지마..
주사위게임 만들 때 멘토님이 하신 말씀이 있는데 "먼저 되는 코드를 만들고 그다음에 수정!" 이 말이 생각나서 그랬습니다..
Java에 재미 붙이는데 아주 최고였습니다.
그럼 안녕히계세요뿅.